Instruction Tuning Notes
Context
💡 This post assumes familiarity with large language models and their training and finetuning. We cover the idea without deep diving into the technical details.
Pretraining LLMs on “next token prediction” task has proven to show incredible generalisation powers as long as you throw enough data, parameters and compute at it. However, it is possible to get more out of your language model if you finetune it on a smaller set. Many have already experimented with finetuning LLMs on downstream tasks. But you can also improve their generalisation and instruction-following abilities by using a dataset that presents tasks as instructions and expects LLM to predict the output.
What is Instruction Tuning?
“A form of fine-tuning that improves a generative AI model’s ability to follow instructions. Instruction tuning involves training a model on a series of instructions prompts, typically covering a wide variety of tasks. The resulting instruction-tuned model then tends to generate useful responses to zero-shot prompts across a variety of tasks.” - Google Dev Page
Why Instruction Tuning?
Given the scaling law, we can expect models to get better with more dataset and parameters. But it is possible to squeeze out more performance by methods like instruction tuning that allow few-shot learning (also called in-context learning; ICL) and zero-shot learning. This way, user can provide prompts with instructions and expect model to perform tasks accordingly.
Think pretraining as barebones for building world knowledge and instruction tuning as lessons on problem solving.
How?
It’s simple, just use the dataset with an input construction as described below. Different models use different approaches but the idea is same, provide instructions that have details of the task and then ask model to predict the output.

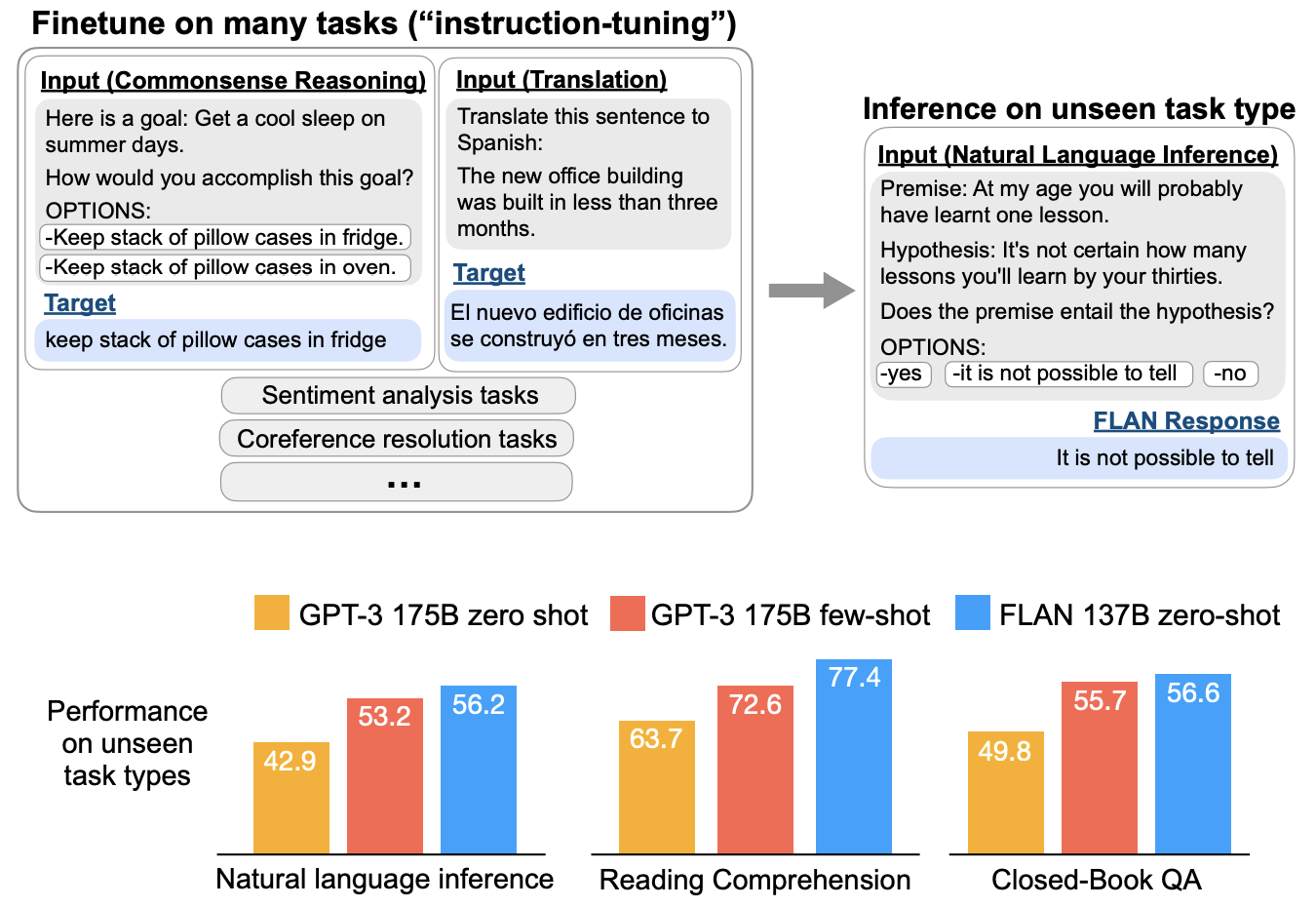
ref(FLAN-T5)
Stanford NLP group released Alpaca: an instruction-tuned model that starts from LLaMA and uses instructions generated by GPT-3 as a dataset
💡 Note on Alpaca: However, the original implementation is less accessible due to licensing constraints of the underlying LLaMA model. Furthermore, users have noted potential noise in the synthetic dataset. Hence, it may be better to explore a fully accessible model that is already trained on high-quality (but less diverse) instructions such as Flan-T5. - flan-alpaca-gpt4-xl
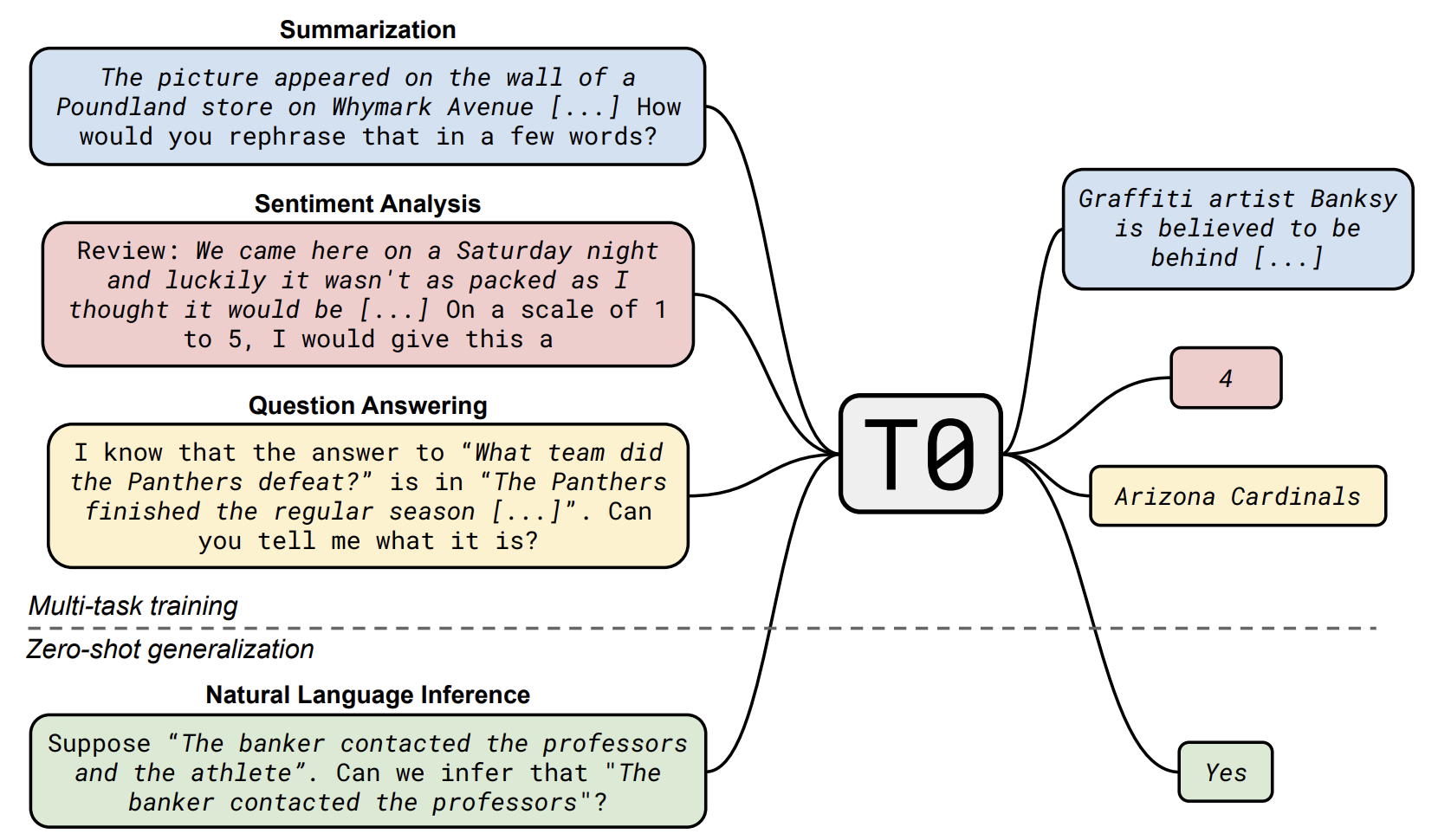
image from T0 paper
Conclusion
It’s nice but the amount of data needed is still pretty large (~10k-100k). Also, deciding the best format for instructions and output is another unbounded experiment.
References
Outerbounds Blog - Beautifully covers Instruction Tuning
Flan-T5 - introduces “instruction tuning”
OpenAI paper Instruct GPT - RLHF with Supervised finetuning step that is instruction tuning
Alpaca - Open source instruction tuned model